Contrary to what you may be thinking this post is about, this post isn't about food or dieting or anything of the sort. In this post I will introduce fibers, also known as coroutines.
Doing two things at once
So, what are these mysterious fibers, and, for that matter, why would you want to use them? Like threads, fibers allow you to work on two tasks at once. Take, for example, the following pseudo-code:
| function breathe() | |
| { | |
| // We have to breathe to survive | |
| } | |
| function walk() | |
| { | |
| // I need to get somewhere | |
| } |
We're going for a walk, so we'll need to run both of the above at once:
| // Create a thread for both tasks so they can execute at once | |
| breathingThread = new Thread(breathe); | |
| walkingThread = new Thread(walk); | |
| // Start doing both of the tasks at the same time | |
| breathingThread.start(); | |
| walkingThread.start(); |
This is simple enough, for each thing we want to do at the same time we define a task, create a thread for it, then run it. Of course, for those of you reasonably familiar with threading, you'll know that it is anything but simple in the real world - it's very easy to create bugs which are very difficult to track down. Let's adapt the functions from above to see this.
| variable amountOfBreathToTake; | |
| function breathe() | |
| { | |
| do | |
| breathe amountOfBreathToTake; | |
| amountOfBreathToTake = 0; | |
| while alive; | |
| } | |
| function walk() | |
| { | |
| do | |
| for every second we walk | |
| increase amountOfBreathToTake; | |
| while alive; | |
| } |
At first glance this seems fair enough - as we walk we need to breathe more, once we've taken a breath we need don't need to breathe again until we have a reason to (for simplicity's sake, we only need to breathe while walking here, and we'll also be walking indefinitely). But there's a problem. We're breathing and walking at the same time. What if walk() tries to increase amountOfBreathToTake at the same time as breathe() sets it to zero? Does amountOfBreathToTake end up as zero? Then we won't take enough breath next time we walk. Does it end up as an increased version of what it was before? Then we'll breathe more air than our lungs can hold. For that matter, why can't amountOfBreathToTake be a random value which is a mixture of the current value, the increased value, and zero? They are both happening at once after all.
How do we avoid this?
The typical way to solve this problem is to introduce a lock. Each time we want to read or write to amountOfBreathToTake, we attempt to lock the lock. If the lock is already locked, we wait until it is unlocked. If it is not locked, we lock it and continue. When we are done reading or writing, we unlock the lock, and someone else is free to lock it. Of course, this has its own problems. What if we introduce a run() function, and forget about the lock? Then we have the same problem again. And how about all the time spent locking, unlocking and waiting, rather than actually walking and breathing?
So let's take a step back. We now have a way to breathe and walk without taking too much or too little breath. We're doing both of these things at the same time. But are we really? We've introduced a lock, so only one of them is actually happening at once! This is where fibers come in. We want to appear to be doing two things at once, but don't actually need to do them at the same time. So, let's modify the code.
| variable amountOfBreathToTake; | |
| function breathe() | |
| { | |
| do | |
| breathe amountOfBreathToTake; | |
| amountOfBreathToTake = 0; | |
| Fiber.yield(); | |
| while alive; | |
| } | |
| function walk() | |
| { | |
| breathingFiber = new Fiber(breathe); | |
| do | |
| for every second we walk | |
| increase amountOfBreathToTake; | |
| breathingFiber.call(); | |
| while alive; | |
| } | |
| walk(); |
There are three main differences to the original code here. First, we only call walk() now, no creating and starting threads. Second, walk() now creates a breathing fiber. Finally, two new method calls have been introduced, one in breathe() and one in walk().
The first we'll look at is breathingFiber.call(); in walk(). If we call breathe() directly, it would enter an infinite loop, where we breathed until we died. We wouldn't continue walking, and our multitasking would be none existant. Of course, we could call walk() from within breathe(), but then every time we breathe we start walking! By using breathingFiber.call(), we call the method in a fiber, so we will still be able to multitask.
The final method call, and the most important, is Fiber.yield(); in the breathe() function. Calling Fiber.yield() causes the currently running fiber to yield to its caller. You can think of it like a return statement, but rather than returning from the function or method, you're returning to the previous state of the program. This does exactly what we want, as breathing doesn't force us to walk, it is still happening at the same time as walking, and we don't have to spend lots of time locking and unlocking.
Let's see some real code
Now for a slightly more involved example. This is done using the D programming language, you should be able to follow along regardless of whether you know it or not, providing you have some experience with object-oriented programming, and a C/Java style language.
In this example, I've filled a room full of malnutritioned people - some how, they've ended up with no iron, no calcium, and no fiber! Of course, this is going to have very serious health impacts if we don't act quickly. So much so, that if we help them one at a time they probably won't make it. So we'll have to feed them all at the same time. First let's define one of our people.
| class Person | |
| { | |
| struct Nutrients | |
| { | |
| int Fiber; | |
| int Calcium; | |
| int Iron; | |
| } | |
| int mNumNutrients; | |
| Nutrients mNutrients; | |
| this(int numNutrients) | |
| { | |
| mNumNutrients = numNutrients; | |
| } | |
| bool satisfied() const nothrow @property | |
| { | |
| return mNutrients == Nutrients(mNumNutrients, mNumNutrients, mNumNutrients); | |
| } | |
| } |
Some notes for people who don't know D:
- D is a typed language, that is, you can't assign a variable a string, then decide you want to put an integer in it. You can infer types using auto, but if you are declaring them without assigning a value to them, you must specify the type. int is a 32 bit integer type, bool is boolean.
- A struct works the same way as in C, it's plain old data. For those of you coming from higher level languages, you can think of a struct as a class without inheritance, it's just a wrapper for some variables and methods.
- All variables are initialised by default to Type.init, see http://digitalmars.com/d/2.0/type.html for a list.
- const, pure, nothrow and @property are attributes, you can find out more about them at http://digitalmars.com/d/2.0/attribute.html. They can be ignored for the sake of this tutorial.
- You can initialise a struct using StructName(firstValue, secondValue, etc).
- this() is the constructor function
- this-> is not required to access member variables
The constructor should be called with the number of nutrients required before the person is healthy. satisfied() will return true when the mNutrients member is equal to a struct containing the required level of nutrients.
We now have to decide how we are going to feed them. We could use either threads or fibers. For the sake of having some pretty graphs and thus some more data to compare and contract with later, I've implemented both (neither of which are very sophisticated). I'll show the Fiber implementation here, however I will attach both at the end. In D, fibers can either be derived from the Fiber class, or composed, by calling Fiber's constructor with the function or method you want it to execute. As we will have a fiber per person, we will use derivation so we can associate the fiber with its person.
| class FeedFiber : Fiber | |
| { | |
| Person mPerson; | |
| this(Person p) | |
| { | |
| mPerson = p; | |
| super(&run); | |
| } | |
| void run() | |
| { | |
| while(!mPerson.satisfied) | |
| { | |
| mPerson.mNutrients.Fiber++; | |
| mPerson.mNutrients.Calcium++; | |
| mPerson.mNutrients.Iron++; | |
| Fiber.yield(); | |
| } | |
| } | |
| } |
Some notes for people who don't know D:
- A colon, ':', is equivilent to extends in Java.
- super() calls the constructor of the parent class.
- The ampersand, '&', takes the address of a variable, method or function. It is used when you want to pass one method or function to another (among other things).
- A period, '.' is used to access members of a class or struct, much like '->' in C++ and PHP.
A FeedFiber will be created for each person, we will then use the .call() method of Fiber, which will call the run() method within that fiber. The code for this could easily be improved, you'll notice it's quite different to how we use fibers above. Rather than using foreach below you could make each fiber yield to the next until they are all satisfied, however I wrote the threaded version first, and I'm lazy. If this post interests you, you could adapt the code and see what difference it makes performance wise and how much nicer the code is.
| void feedWithFibers(int numPeople, int numNutrients) | |
| { | |
| size_t terminated; | |
| auto fibers = new FeedFiber[numPeople]; | |
| foreach (ref f; fibers) | |
| { | |
| f = new FeedFiber(new Person(numNutrients)); | |
| } | |
| while (terminated != fibers.length) | |
| { | |
| foreach (ref f; fibers) | |
| { | |
| if (f) | |
| { | |
| // The fiber has run to completion | |
| if (f.state == Fiber.State.TERM) | |
| { | |
| terminated++; | |
| f = null; | |
| continue; | |
| } | |
| f.call(); | |
| } | |
| } | |
| } | |
| } |
Some notes for people who don't know D:
- void means 'no type'
- size_t is the type used to represent the length of an array. It's length varies depending on the arcitecture of the computer you are using, it is unsigned in all cases.
- auto is used to infer type.
- new MyClass[number] results in an empty dynamic (number of elements can vary) array of MyClass with number number of elements.
- foreach is used to iterate over elements in an array, it is in form foreach(index, element; array){}, index is optional and the type of each is infered (although can be stated explicitly)
- If ref is placed before the element name in foreach, you will receive a reference to the value in the array, allowing you to mutate the array.
- All arrays have the property length, which returns the length of the array
Here we create a fiber for each person, then loop over the fibers, calling each until the given fiber terminates - when the fiber's function returns rather than yielding. When it does, we increment a counter and set the fiber to null, then move onto the next fiber until there are no fibers left to operate on, that is, we've fed all the people and they're no longer malnutritiened. The final thing to do is actually call this method.
| void main(string[] args) | |
| { | |
| // Check for valid arguments | |
| enforce(args.length == 3); | |
| int numPeople = to!int(args[1]); | |
| int numNutrients = to!int(args[2]); | |
| StopWatch sw; | |
| // Time feeding with threads | |
| sw.start(); | |
| feedWithThreads(numPeople, numNutrients); | |
| sw.stop(); | |
| writef("%s, ", sw.peek().usecs); | |
| sw.reset(); | |
| // Time feeding with fibers | |
| sw.start(); | |
| feedWithFibers(numPeople, numNutrients); | |
| sw.stop(); | |
| writefln("%s", sw.peek().usecs); | |
| } |
Like C, D uses the main() method for program entry, with an array of strings as the arguments. The program will accept two arguments, the number of people, and the number of nutrients each person needs. We first check for the correct number of arguments - this is three as the first argument is always the path to the application. We then convert the strings to integers so we can use them as such - to!() will throw an exception if a valid integer isn't passed. Strictly speaking we should be using size_t throughout the application - as I mentioned above arrays have a length of type size_t, and we are using these numbers to specify the length of the array. If you use a negative number as the first parameter it will cause an error, and a negative for the second will lead to an incredibly long runtime - the integer will have to overflow before the correct number of nutrients is hit. Once this is fixed, a nicer error could be given - look at the beautiful stack traces you get if you don't use enough parameters or try and pass a non-integer for the arguments.
The next two chunks of code do two things - start and stop a stopwatch so we can time how long each takes, and feed people using both threads and fibers (you can see the code for the former at the end of the post). The output is written in csv format to allow output to easily be plotted.
So which is faster then?
Let's look at some graphs of the output. Each graph is created using the output of this command, using the number of nutrients given in the graph's title, and a number of people from 1 through 2048. The application was compiled as follows:
$ dmd -O -release -inline main.d
Using dmd v2.052 on OS X 32bit. The machine in question has a 2.2Ghz Core 2 Duo CPU (dual core) and 2GB ram.
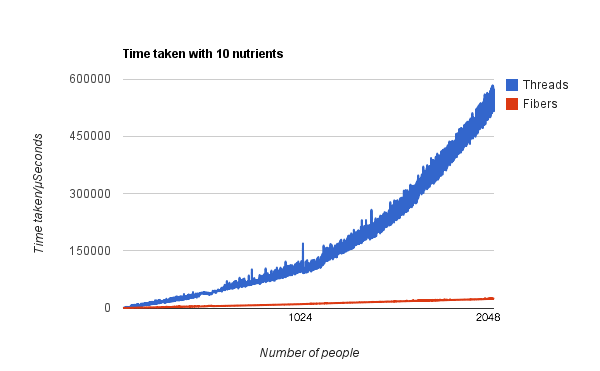
As you can see, with ten nutrients there is a huge difference between threads and fibers - the time taken to feed the masses with fibers scales linearly with the number of people. When using threads it is fairly linear until about one thousand threads, where the time taken per each additional person is far greater.
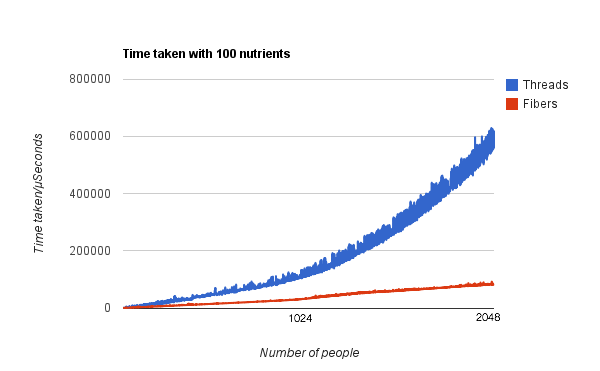
If we increase the number of nutrients by an order of magnitude, we see a similar trend, however threads now have a lower gradient, leading to a more curve like shape - they are still far slower however.
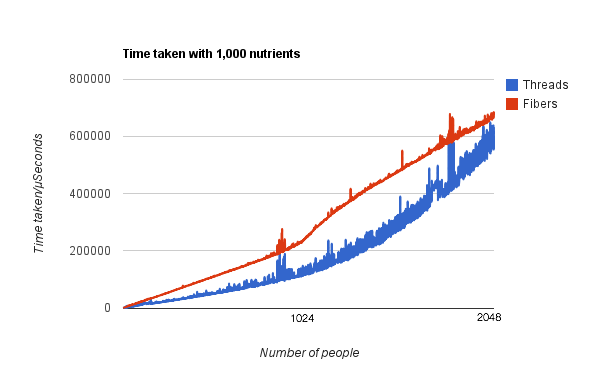
With another order of magnitude we see some more interesting results. Threads have overtaken fibers in performance. There are also some more noticable spikes in the graph at this point. This is entirely my fault, as I generated these statistics on my laptop which I was using for other things. This resulted in additional context switches being required, which had a dramatic effect on some of the numbers, particularly when using threads. I've ironed out the more anomylous results, there are still a few which need fixing though. Ideally I would rerun the benchmarks on a computer which isn't doing anything else.
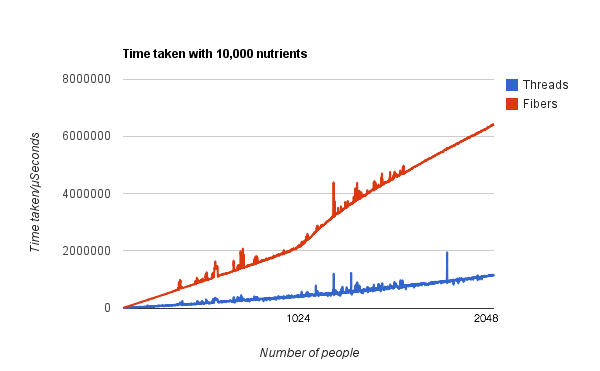
The final step up in magnitude leads to both threads and fibers appearing to scale linearly, but now fibers use up a lot more time.
What does this data actually mean?
Let's start with the obvious. The overhead of using fibers scales (fairly) linearly under all the tested workloads, and it'd be a fair bet to say this trend continues. This is an excellent thing - no matter what you're doing, you can keep adding tasks and scale the hardware with it. Threads on the other hand tend to be anything but linear until you have a certain workload - each time you add a task, the next task will need twice as many resources (or there abouts) as the last task. This is definitely not a good thing.
The next thing to notice is that as the workload increases, threads become a far more appealing. They become closer and closer to scaling linearly, and use less time. Fibers, on the other hand, take up a lot more time - after all, there's only so much work one processor core can do. Let's not forget however, that you can have multiple fibers per thread - you could take a hybrid approach and get the best of both worlds.
So how do I decide on the best approach?
The first thing you should look at is what you are trying to do. How many tasks will you have to do? How processor intensive are these tasks, and how does this compare to anything else your application is doing? Clearly if you're doing a few expensive tasks, threads are the way to go. If you're doing lots of cheap tasks fibers are the way to go - the overhead of creating threads will likely outweigh the tasks themselves. In the middle ground you can take the hybrid approach, both threads and fibers. Or, even better, processes and fibers. By using processes instead of threads you remove the need to worry about synchronisation, and if one process crashes, the others are still in tact.
There is also the issue of deciding what is expensive and what isn't. The chances are if you're doing any kind of IO, whatever processing you're doing is negligible in comparison. Rather than using blocking, synchronous IO, you could switch to non-blocking and asynchronous IO, allowing you to process data for other IO sources while you wait. In the case of networking, this is what the fastest webservers (nginx, lighttpd, etc) do, in combination with epoll, kqueue and similar.
If you still aren't sure which you should be using (or even if you are!) try benchmarking and profiling each to see which performs better with whatever task you happen to be doing.

3 comments for "Getting more fiber in your diet"
Nice article!
Here's my results with 1024 people and increasing nutrients by orders of magnitude:
dmd -release -O -inline -noboundscheck fibertest.d
fibertest.exe 1024 10
Threads: 51_292, Fibers 6_293
fibertest.exe 1024 100
Threads: 51_290, Fibers 27_430
fibertest.exe 1024 1000
Threads: 50_043, Fibers 239_674
fibertest.exe 1024 10000
Threads: 107_626, Fibers 2_381_763
fibertest.exe 1024 100000
Threads: 799_746, Fibers 23_982_260
I'm on XP32, running a quad-core Athlon II X4 620 @ 2.61Ghz, 3GB RAM.
How did you make those charts? I'd like to make them too, to compare against your results.
Sorry for the slow reply! I used Google speadsheets - there's a chart tool in there. Take a look at the links at the bottom, should show you how to do it.
Well done article. But the results are not really meaningful..
After a short look to the source code I've noticed that:
- Threads would execute many loop iterations without context switch. The may even finish before the first context switch.
- Fibers/coroutines perform in every loop-iteration a context switch back to the callee
Also are the operations taken on that struct are really cheap, so in the fiber case the most time is spent by call() and yield(). In the last case where 2048 people want 10000 nutrients, yield() and call() is called (2048 * 10,000) over 20 million times.
While in the thread case the loop is executed many many times without context switch.
That means 20 million single-threaded context-switches are compared to only a few thousand os-thread-context switches which run on 4 cores.
Conclusion Fibers vs. Threads:
=== Pros ===
• Fiber context switches are way more cheaper than thread-context-switches from the os.
• Fibers also have the advantage ( because they are running inside the current thread) that no synchronization is needed.
=== Cons ===
• Multiple threads can be executed simuntaneously. Fibers are executed inside a single-thread.
The best would be to combine fibers with threads. So that many work-fibers are executed by a few threads simultaneously.